Enabling blue/green deployments and split testing on API Gateway: a modest proposal
In my talk at Serverlessconf London, I presented an idea I had for reducing the pain of deploying APIs with API Gateway.
API Gateway provides stages to allow you to have multiple deployed APIs under the same gateway. In theory, you could have a dev, test, and prod stages, and promote a new API deployment through those stages. In practice, though, no one wants to do an in-place update of an API. Incremental rollouts are needed. At iRobot, this has led us to always create a new API Gateway every time, always with a single stage. The Serverless framework takes this approach as well. We use a service discovery service for our clients to discover our API endpoints, and we use it to do incremental rollouts by initially transferring only a small number of clients over the new deployment. This strategy can also be used to do split testing (A/B, etc.), where eventually the clients get rolled back to the original deployment.
It’s great that API Gateway is capable of in-place updates with no downtime. But in-place updates are the naïve deployment strategy, and don’t support split testing. So I got to thinking about how API Gateway could support incremental rollouts within its existing model.
Imagine we have an API deployed on API Gateway we want to update. The update doesn’t change the client-facing side of API, but changes the Lambda integration of some method, say /v1/users/{user_id}. We have a stage deployed, which we’ll call blue. We deploy the updated API to a stage called green.
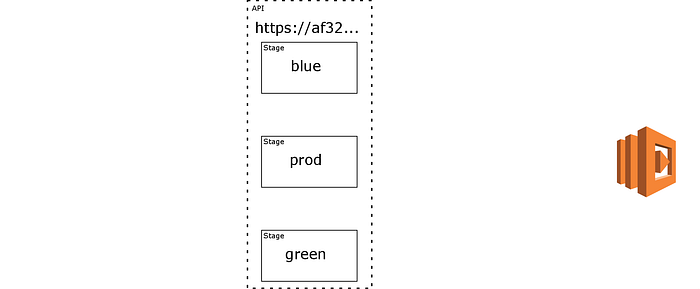
Now suppose we have a different kind of stage, a routing stage, deployed, with the name prod. This stage has no paths in it, no integrations. It contains two things: a list of other stages on the same API, and an ARN for a Lambda function called the router along with a client id HTTP header name. This is the stage the client invokes.
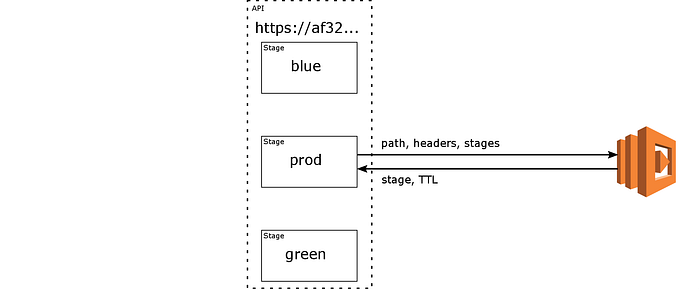
So suppose a new client sends a request to the prod stage with some path. After getting past the custom authorizer step (if one is set), the router Lambda is invoked with the HTTP path, method, and headers, and the list of stages as input. It returns a stage name (which must be from the list), and a TTL. The client’s request is then invoked on the corresponding stage. API Gateway identifies this client by the configured header name, and remembers the choice of stage for the client for the given TTL.
Suppose we’ve configured the prod stage to use x-client-id for the client id header. We could implement a router Lambda function that takes three configuration parameters (retrieved from a DynamoDB table), a percentage, a short TTL, and a fixed time in the future, the expected maximum completion time of the rollout. When invoked, the function chooses green for the given percentage of client ids, giving a TTL until the fixed time, otherwise choosing blue with the short TTL.
A way to implement the previous strategy (h/t Rob Gruhl) is to hash the id (plus a salt) into 100 buckets, and assign green to the first X buckets corresponding to the percentage. To reset/shuffle the assignments, the salt can be changed.
To start, the percentage is set to 10%, the short TTL set to 5 minutes (300 seconds), and the future time is set to 2 hours (7200 seconds) ahead, the maximum expected duration of the rollout.
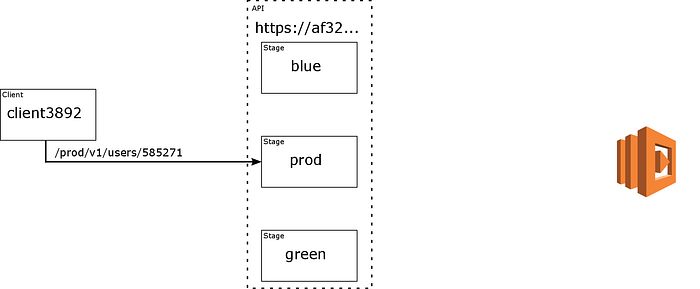
A new client executes an HTTP GET against af32.us-east-1.execute-api.amazonaws.com/prod/v1/users/585271, setting the x-client-id header to client3892.
The router Lambda is invoked…
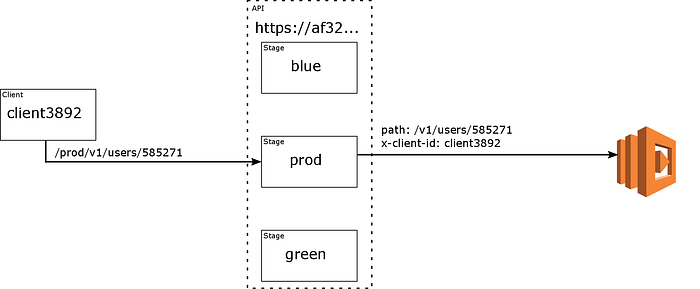
…and randomly chooses blue.
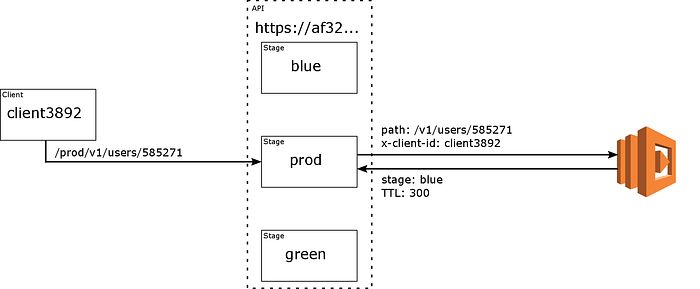
The path /v1/users/585271 is invoked on the blue stage, indistinguishable from if the client had invoked af32.us-east-1.execute-api.amazonaws.com/blue/v1/users/585271.

Another client executes an HTTP GET against af32.us-east-1.execute-api.amazonaws.com/prod/v1/users/685432, setting the x-client-id header to client5721.
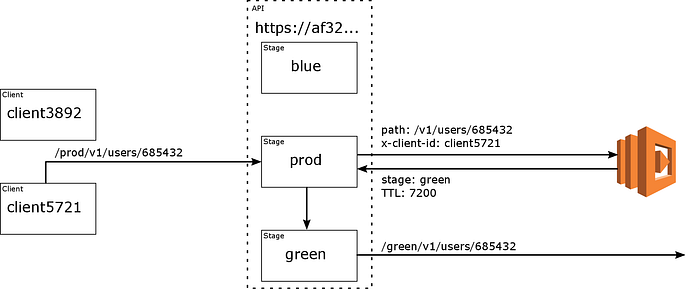
The router Lambda chooses green, and /v1/users/685432 is invoked on the green stage. This client is routed to green for the next two hours.
Five minutes later, client3892 executes an HTTP POST against af32.us-east-1.execute-api.amazonaws.com/prod/v1/users/341341/foo. There is no resource corresponding to this path on either the blue or green stage. As the TTL has expired, the router Lambda is invoked again, and this time it chooses green. The path /v1/users/341341/foo is invoked on the green stage. Only at this point does the API recognize the incorrect path and return an error to the client. This means no verification of the path needs to take place in the routing stage.
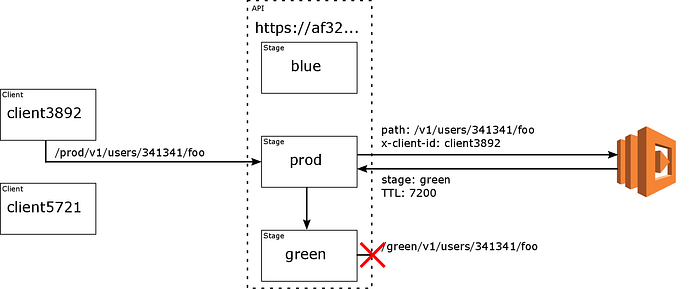
After 30 minutes, traffic through the green stage has enabled the administrators to be confident in the new deployment, and the percentage is increased to 50%. As more traffic rolls over, the new deployment warms up, and eventually the percentage is increased to 100%. Once the traffic completely drained off the blue stage, it can be removed.
Much more complicated router Lambdas are possible, and relatively simple routers could be implemented by API Gateway and provided as an option.
A feature like the one presented here would allow API Gateway to support phased updates to systems using it, something that is not currently possible with a single API endpoint, and not possible through other serverless API offerings.







